
有时候我们可能会把CSV中的数据导入到某个数据库的表中,比如做报表分析的时候。
对于这个问题,我想一点也难不倒程序人员吧!但是要是SQL Server能够完成这个任务,岂不是更好!
对,SQL Server确实有这个功能。
首先先让我们看一下CSV文件,该文件保存在我的D:盘下,名为csv.txt,内容是:
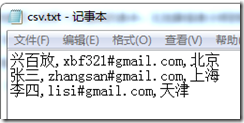
现在就是SQL Server的关键部分了;
我们使用的是SQL Server的BULK INSERT命令,关于该命令的详细解释,请点击此处;
我们先在SQL Server中建立用于保存该信息的一张数据表,
CREATE TABLE CSVTable(
Name NVARCHAR(MAX),
Email NVARCHAR(MAX),
Area NVARCHAR(MAX)
)
然后执行下面的语句:
BULK INSERT CSVTable
FROM ‘D:csv.txt’
WITH(
FIELDTERMINATOR = ‘,’,
ROWTERMINATOR = ‘n’
)
SELECT * FROM CSVTable
按F5,执行结果如下:
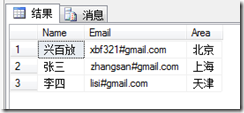
怎么样?是不是比用程序简单!
但是现在有几个问题需要考虑一下:
1,CSV文件中有的列值是用双引号,有的列值则没有双引号:
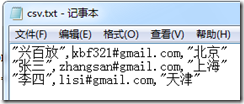
如果再次运行上面的语句,得到结果就和上一个结果不同了:
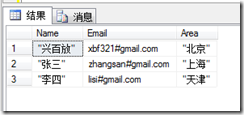
其中有的列就包含双引号了,这应该不是我们想要的结果,要解决这个问题,我们只能利用临时表了,先把CSV导入到临时表中,然后在从这个临时表中导入到最终表的过程中把双引号去掉。
2,CSV文件的列值全部是由双引号组成的:
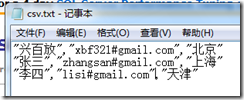
这个问题要比上一个稍微复杂点,除了要先把CSV文件导入到临时表中,还必须修改一下在把CSV文件导入到临时表的代码:

注意圈中的部分。
3,CSV文件的列要多于数据表的列:
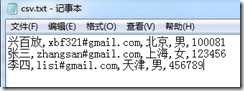
而我们的数据表只有三列,如果在执行上面的导入代码,会产生什么结果呢?
结果就是:
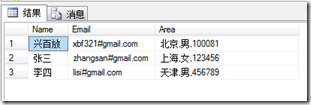
它把后边的全部放在了Area列中了,要处理这个问题,其实也很简单,就是我们把我们想要的列值在数据表中都按顺序建立一列,而把不需要的列值,也在数据表中建立一个,只不过只是一个临时列,在把这个数据表导入到最终表的时候,忽略这个临时列就行了。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
Linux支持的引入 推动了SQL Server 2016集成服务的发展
随着SQL Server的不断发展,集成服务也在发生相应的变化。在最新的SSIS更新中,增加Linux支持和SQL Server 2016升级向导。
-
Notre Dame对云端SQL Server性能基准的探索实践
确立SQL Server的性能基准,对于云端迁移来说是至关重要的第一步,一位来自于University of Notre Dame 的DBA表示,他正在试图通过数据库监控软件,找出SQL server的性能基准。
-
横向扩展SQL Server应用程序:提高工作负载的选项
SQL Server管理员面临的最大挑战之一就是扩展数据库以适应更为繁重的数据处理工作负载。然而事情越发复杂的是,虽然Microsoft提供了许多不同的SQL Server可扩展性选项,但它们并不都适合于每种情况。
-
五大技巧构建首个SQL Server容器
容器的世界庞大而复杂,使用者可能会感到困扰,这里我们将列出一些示例,以便引导您顺利完成SQL Server容器的创建和管理。